with open('data.txt', 'r') as file: res_list = [] lines = file.readlines() print('[+]去重之前一共{0}行'.format(len(lines))) print('[+]开始去重,请稍等.....') for i in lines: if i notin res_list: res_list.append(i) print('[+]去重后一共{0}行'.format(len(res_list))) print(res_list)
with open('data1.txt', 'w') as new_file: for j in res_list: new_file.write(j)
1 2 3 4 5 6
import binascii
with open('data1.txt','r') as file: with open('data2.txt','wb') as data: for i in file.readlines(): data.write(binascii.unhexlify(i[:-1]))
code_str = 'etaonrhisdluygw' code_dict = {'a':'dIW','b':'sSD','c':'adE ','d':'jVf','e':'QW8','f':'SA=','g':'jBt','h':'5RE','i':'tRQ','j':'SPA','k':'8DS','l':'XiE','m':'S8S','n':'MkF','o':'T9p','p':'PS5','q':'E/S','r':'-sd','s':'SQW','t':'obW','u':'/WS','v':'SD9','w':'cw=','x':'ASD','y':'FTa','z':'AE7'} base_str='' for i in code_str: i = code_dict[i] base_str += i print(base_str)
defbin_to_str(s): return''.join([chr(i) for i in [int(b, 2) for b in s.split(' ')]]) a = "01101100 00101100 00001100 01101100 10011100 10101100 00001100 10000110 10101100 00101100 10001100 00011100 00101100 01000110 00100110 10101100 01100110 10100110 01101100 01000110 01101100 10100110 10101100 01000110 00101100 11000110 10100110 00101100 11001100 00011100 11001100 01001100" a = a.split(' ') flag = '' for i in a: test = i[::-1]#::-1表示将字符串倒序,因为题目提示屁股,我们可以考虑是反着来的。 flag += bin_to_str(test)

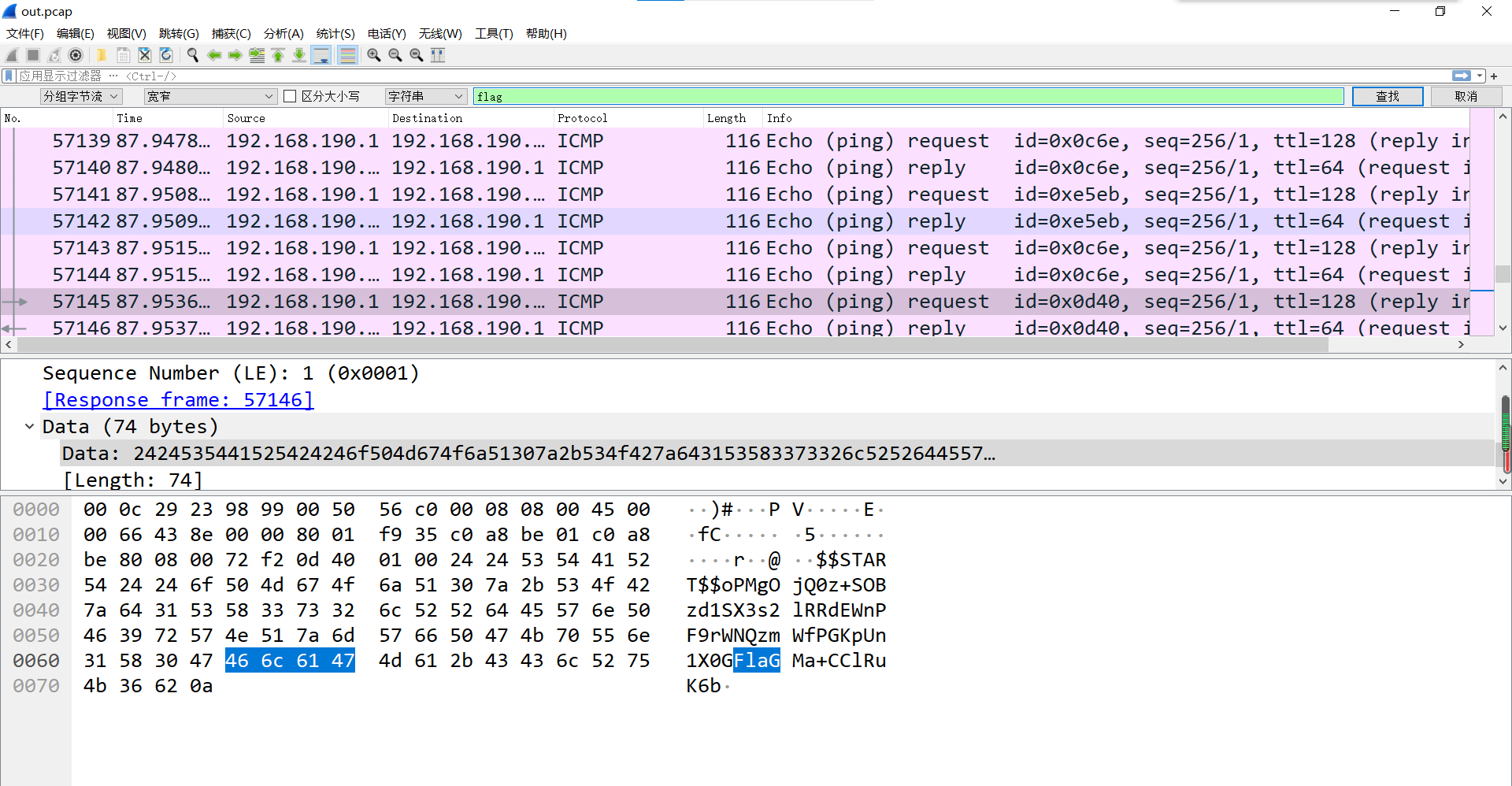 image-20210725203301812
image-20210725203301812 image-20210725214344375
image-20210725214344375 image-20210725222335707
image-20210725222335707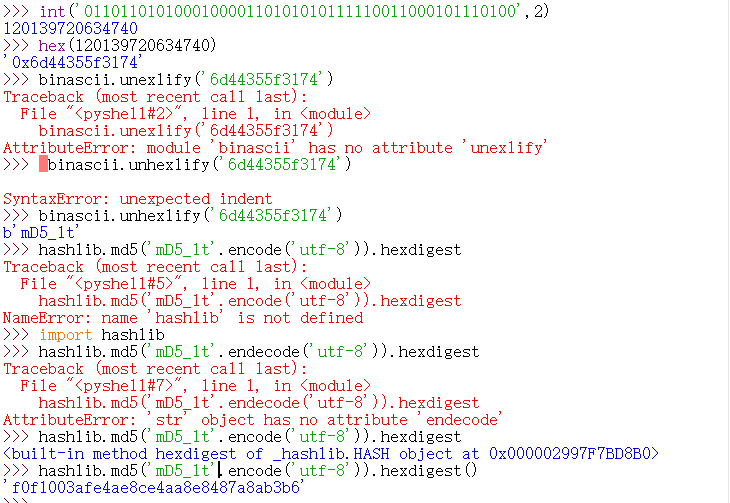 image-20210725222407280
image-20210725222407280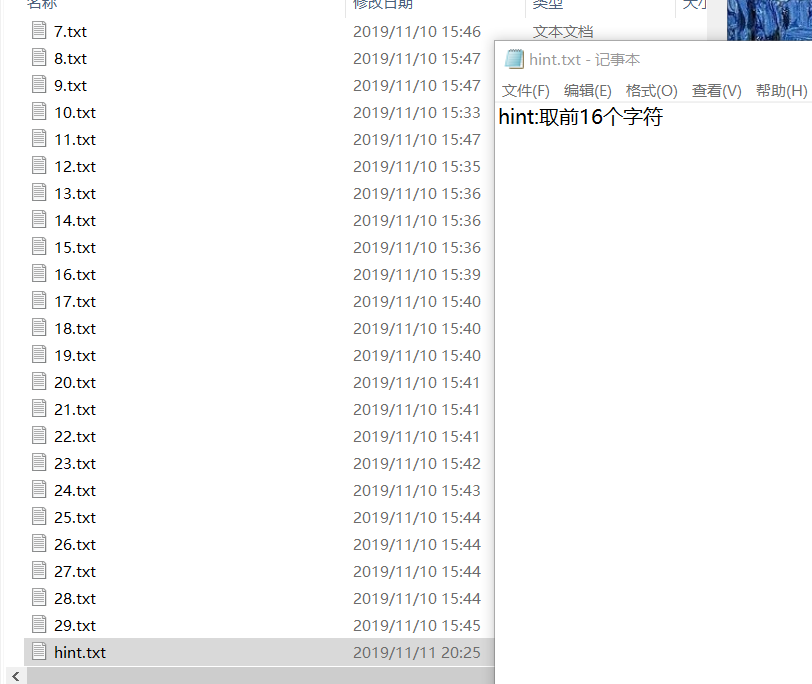 image-20210727145442105
image-20210727145442105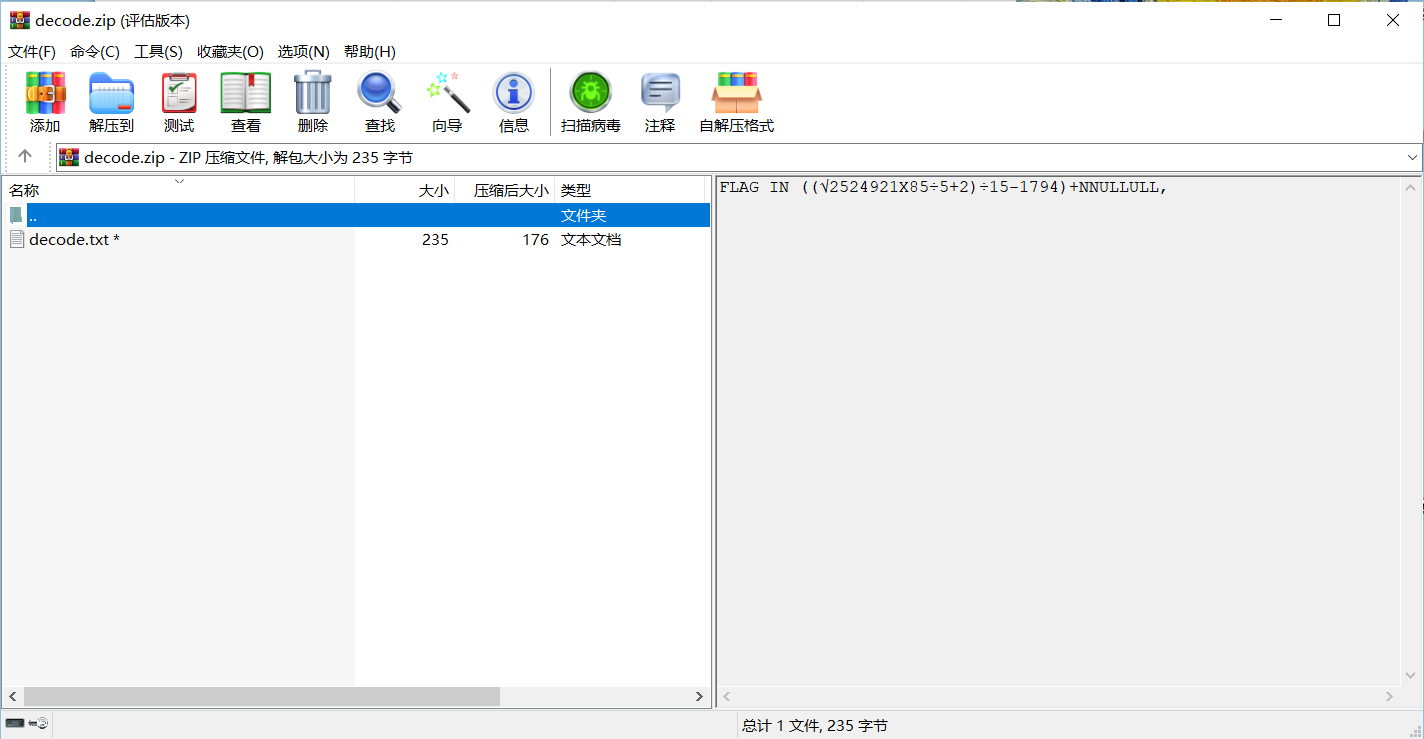 image-20210727145635019
image-20210727145635019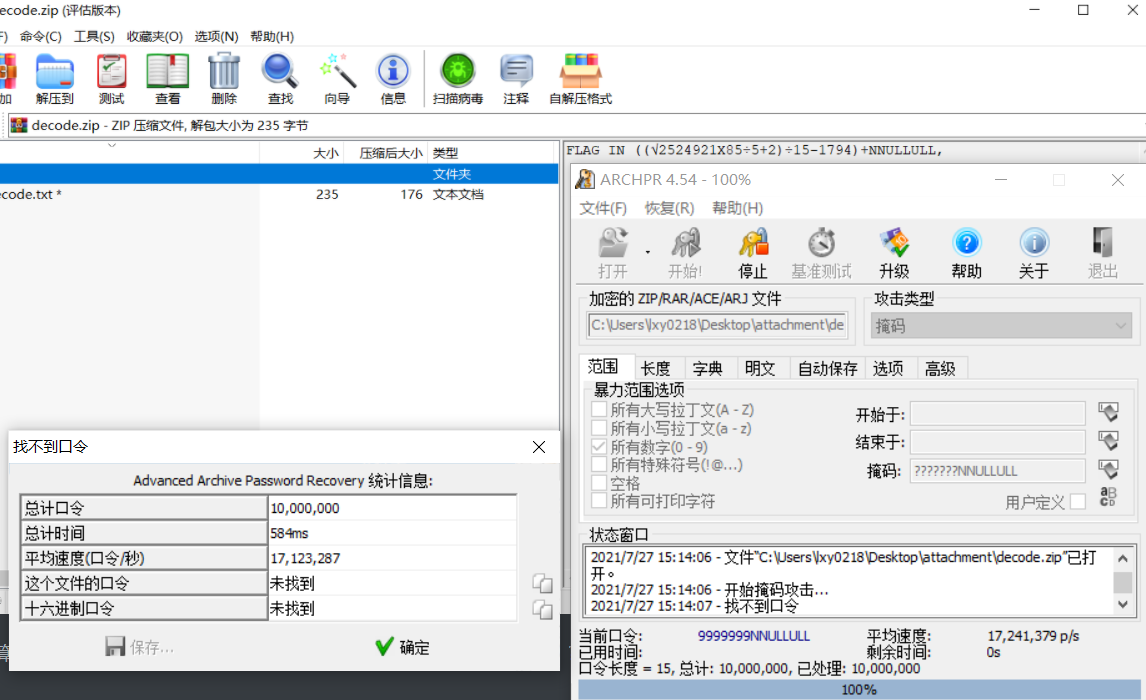 image-20210727151421374
image-20210727151421374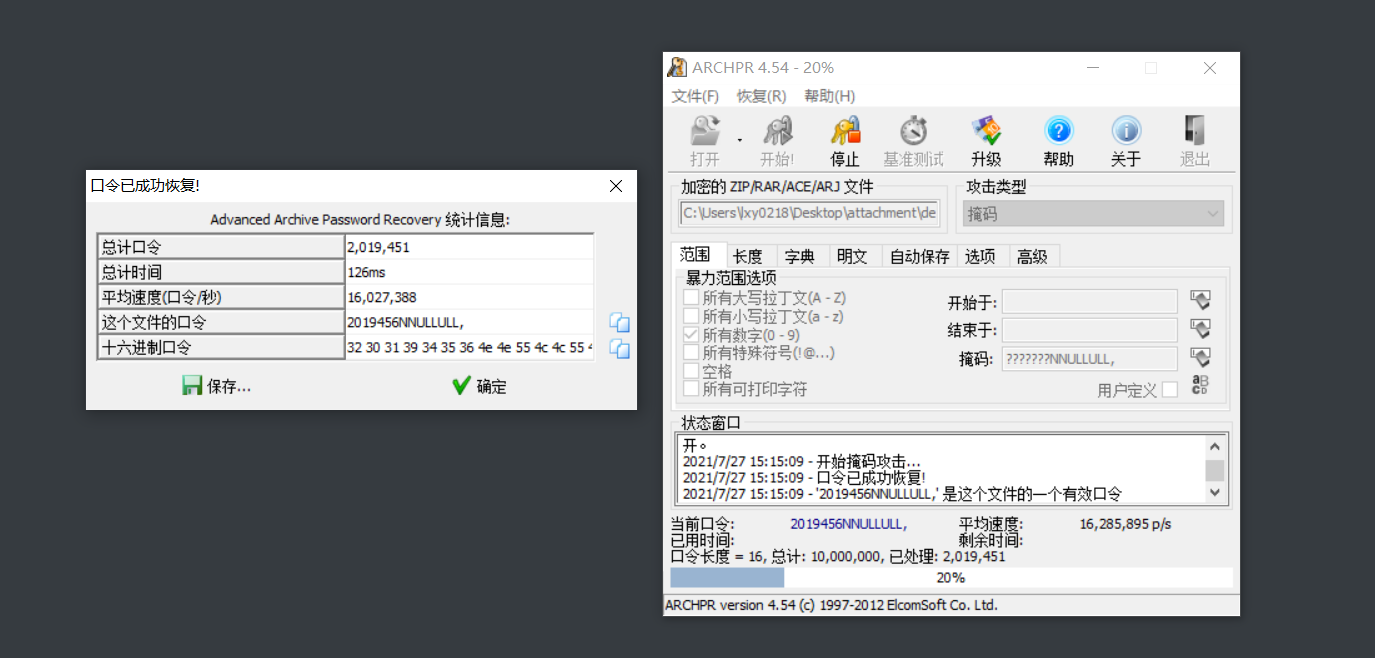 image-20210727151519561
image-20210727151519561 image-20210727151720687
image-20210727151720687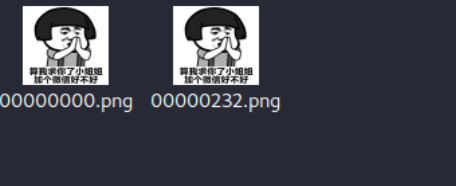 image-20210727152405044
image-20210727152405044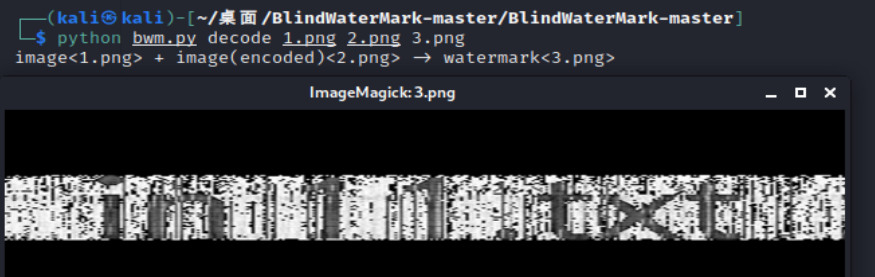 image-20210727195327835
image-20210727195327835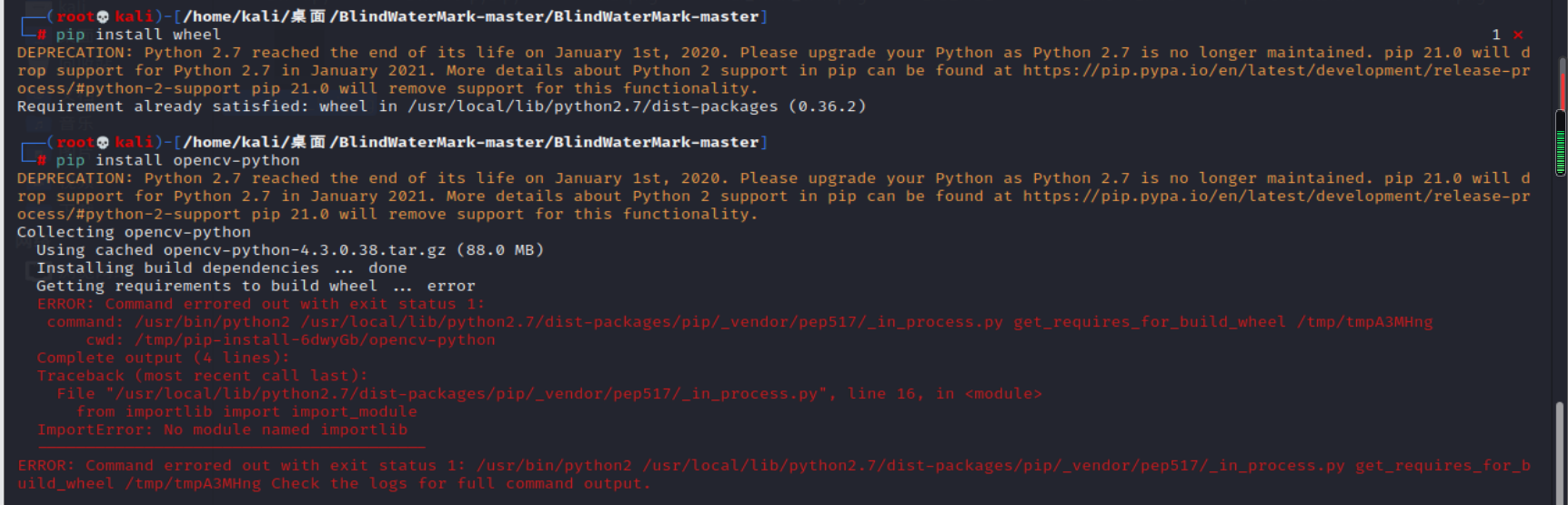 image-20210727180515713
image-20210727180515713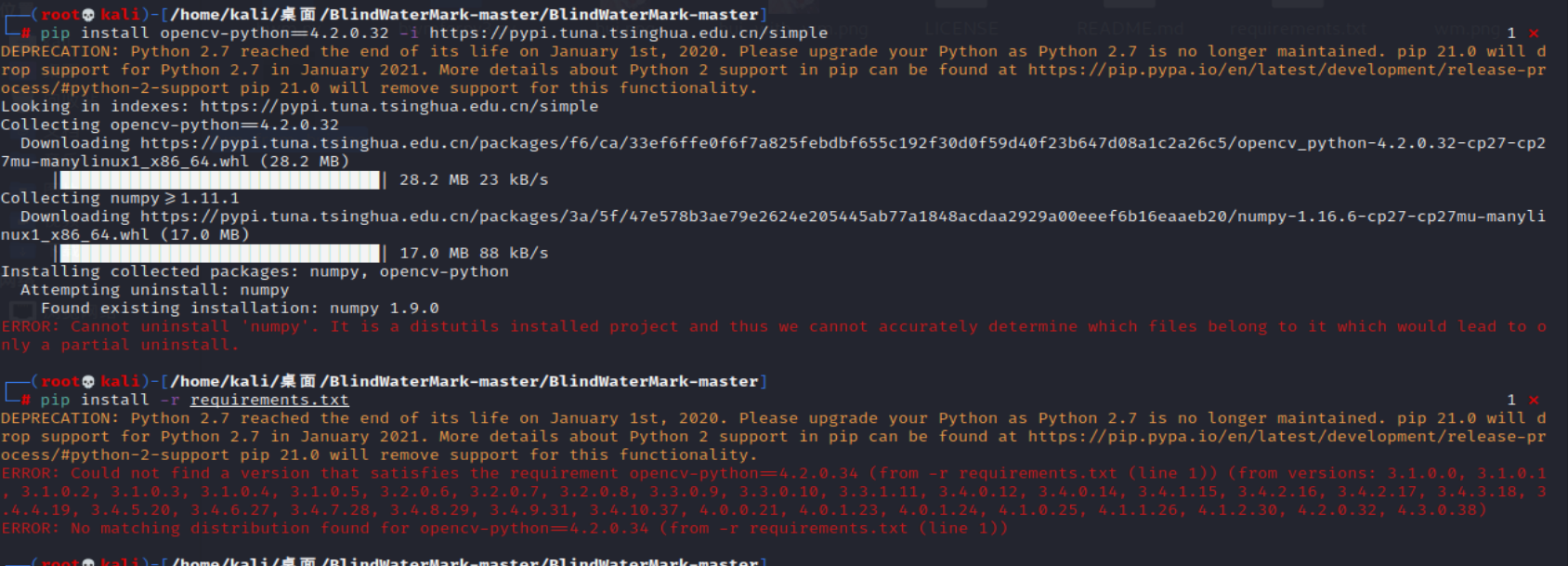 image-20210727181045672
image-20210727181045672 image-20210727181330184
image-20210727181330184 image-20210727181500305
image-20210727181500305 image-20210725225452816
image-20210725225452816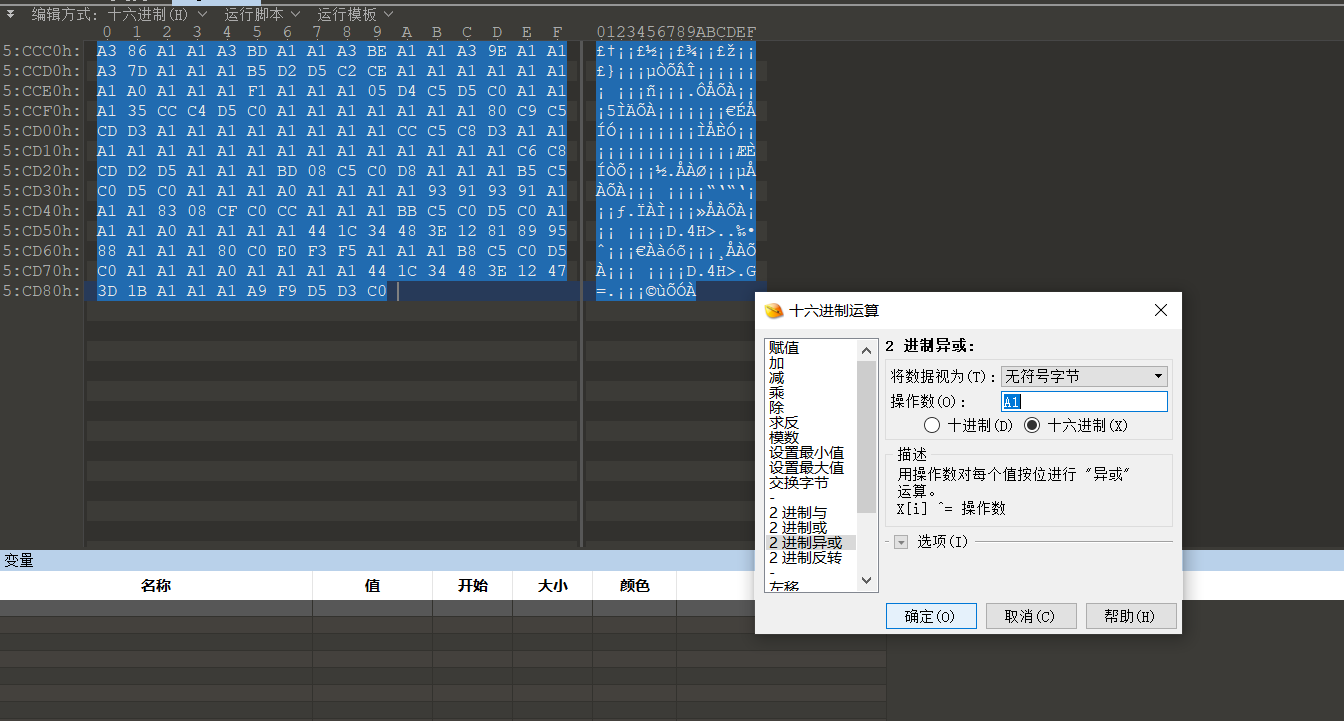 image-20210725225604231
image-20210725225604231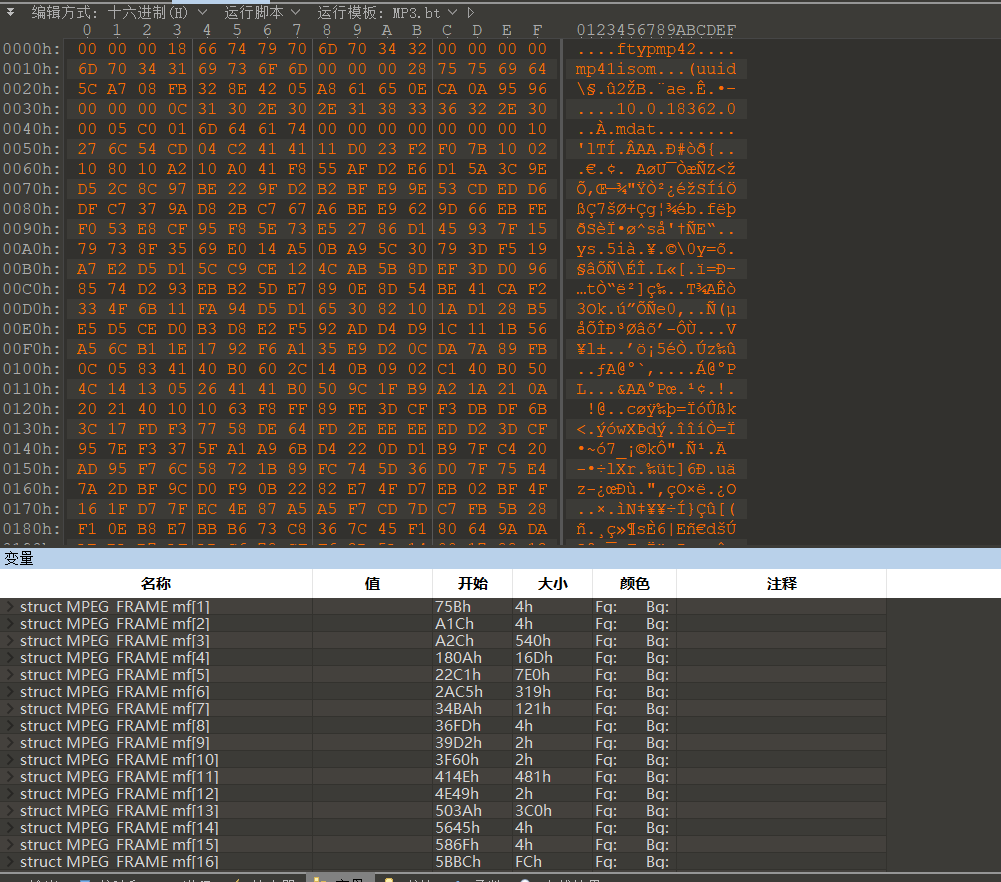 image-20210725225703781
image-20210725225703781 image-20210725235851959
image-20210725235851959 image-20210726233226028
image-20210726233226028 image-20210726234251079
image-20210726234251079 image-20210726235005308
image-20210726235005308 image-20210726235505167
image-20210726235505167 image-20210726235600081
image-20210726235600081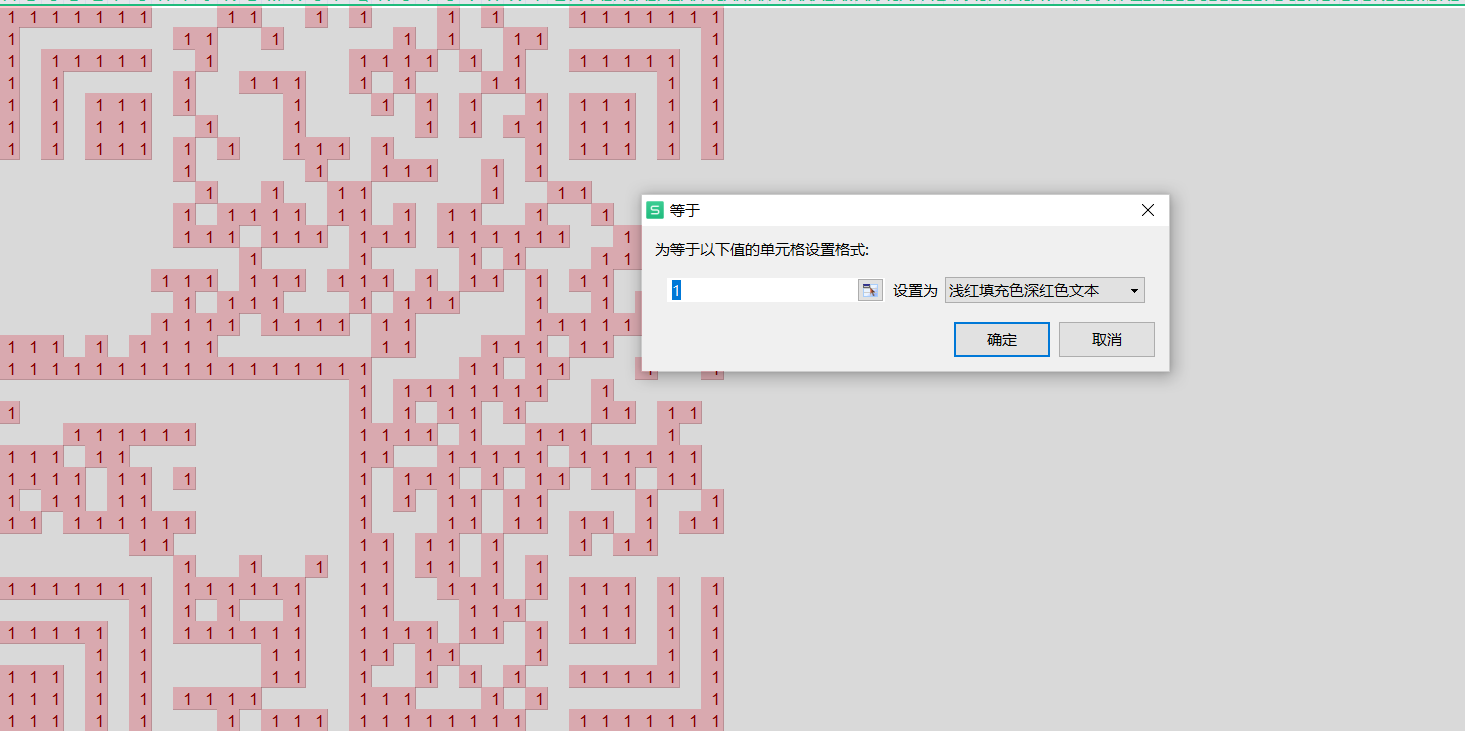 image-20210726235647659
image-20210726235647659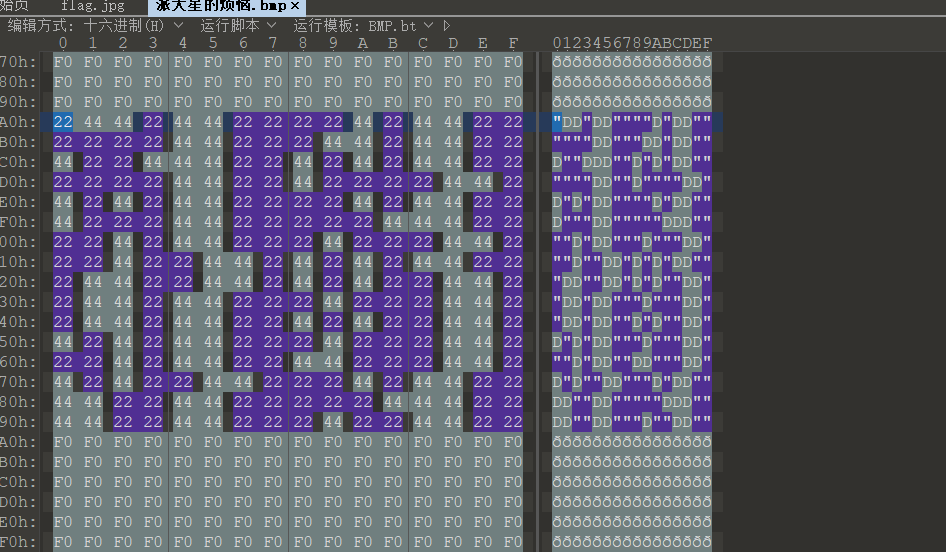 image-20210727160231064
image-20210727160231064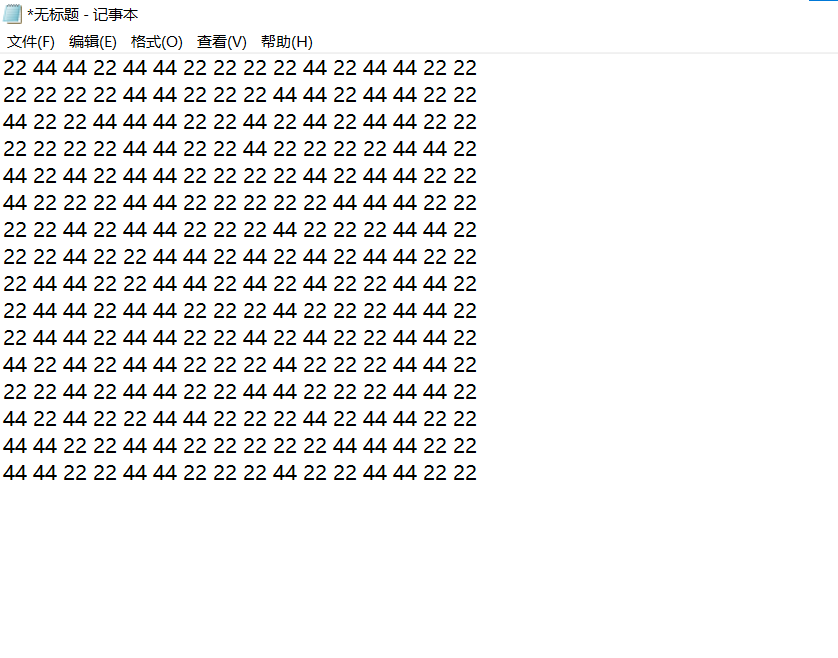 image-20210727160814220
image-20210727160814220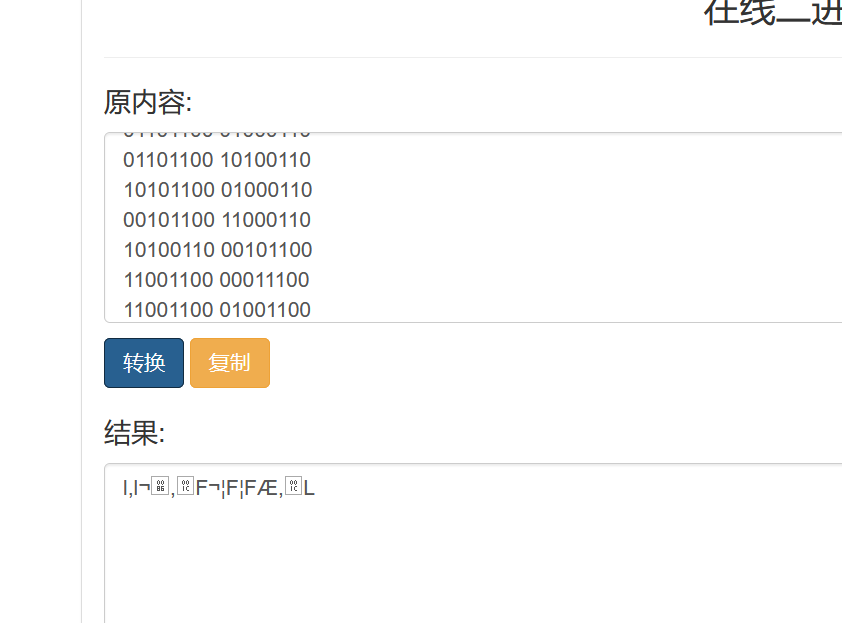 image-20210727162154990
image-20210727162154990 image-20210727162246807
image-20210727162246807